효율적인 RAG 구축 솔루션
PDF 문서에서의 정확한 텍스트 추출은 고품질 RAG 시스템 구축의 핵심입니다.
기존 오픈소스 솔루션의 한계를 극복한 Structum의 최적화 모델은 개인부터 기업까지 안정적이고 경제적인 RAG 구축을 가능하게 합니다.
주요 특징
- 정확한 문서 구조 추출
- 비용 효율적인 처리
- 빠른 통합 및 배포
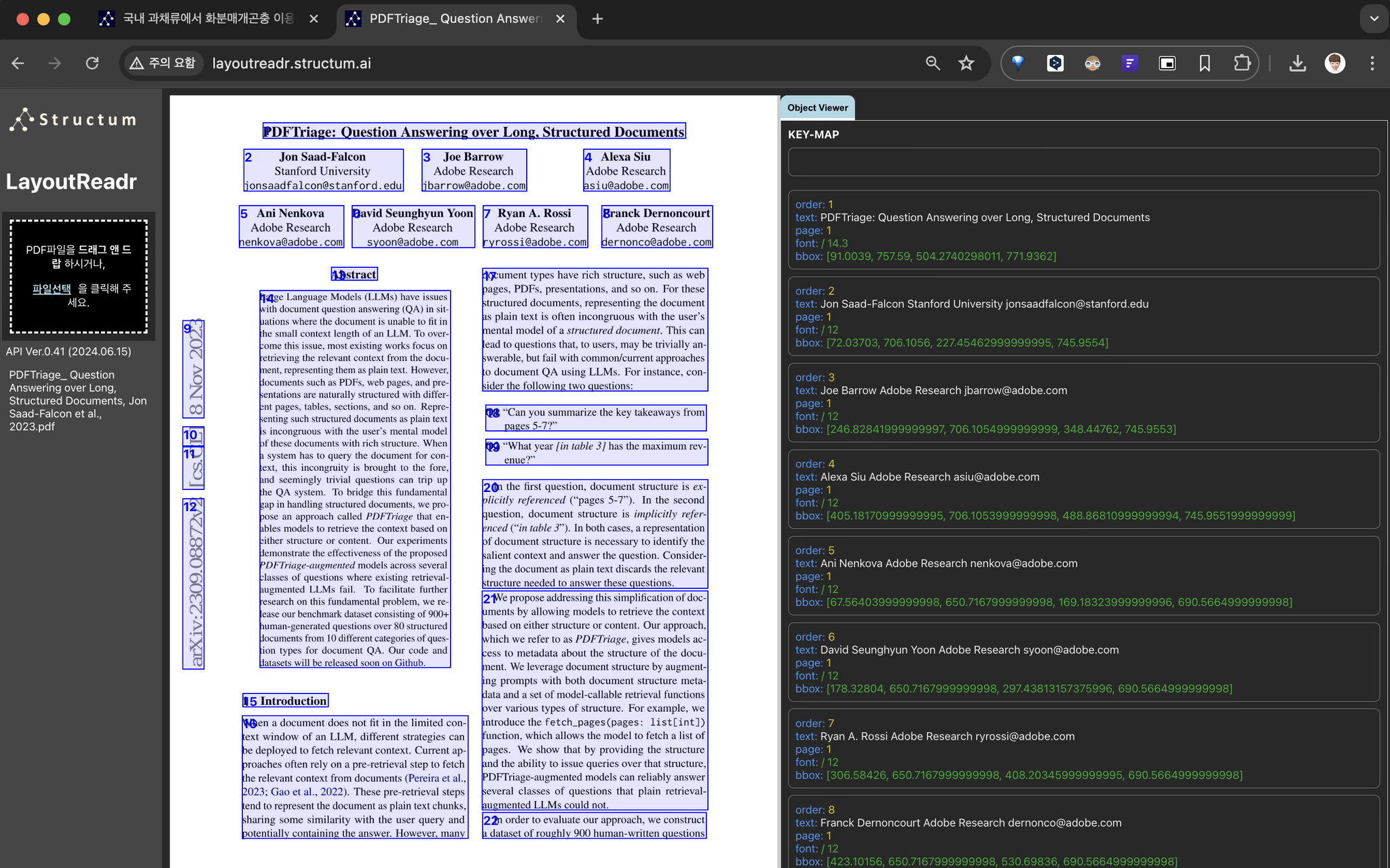
Extract Structure from your PDF
PDF 문서에서의 정확한 텍스트 추출은 고품질 RAG 시스템 구축의 핵심입니다.
기존 오픈소스 솔루션의 한계를 극복한 Structum의 최적화 모델은 개인부터 기업까지 안정적이고 경제적인 RAG 구축을 가능하게 합니다.
알고리즘 기반 처리와 딥러닝 기술을 최적으로 결합한 솔루션
Structum은 알고리즘 기반 처리와 딥러닝 기술을 최적으로 결합하여, 일반적인 GPU 중심 솔루션 대비 10분의 1 수준의 GPU 리소스만을 사용합니다.
이미지 처리가 필수적인 영역에만 선택적으로 GPU를 활용하여 다양한 문서 유형에서 정확한 레이아웃 추출과 비용 효율성을 동시에 달성했습니다.
💡 경쟁력 있는 가격의 API 서비스를 준비 중입니다.
개인 개발자부터 대기업까지, 규모와 상관없이
누구나 활용할 수 있는 실용적인 문서 AI 기술을 제공합니다.
모든 문서 유형, 파일 포맷, 레이아웃 구조를 지원합니다.
문서의 핵심 메타데이터를 자동 추출하여 효율적인 분류 및 검색을 지원합니다.
다중 문서에 대한 자동화된 데이터 추출 및 분석으로 핵심 업무에 집중할 수 있는 환경을 제공합니다.
기업의 특수한 정보 처리 요구사항에 맞춤화된 문서 처리 솔루션을 제공합니다.
복잡한 문서 구조도 정확하게 분석하고 추출합니다
복잡한 다단 구조, 혼합 레이아웃에서도 정확한 문서 구조를 파악하고 논리적 읽기 순서를 보존합니다.
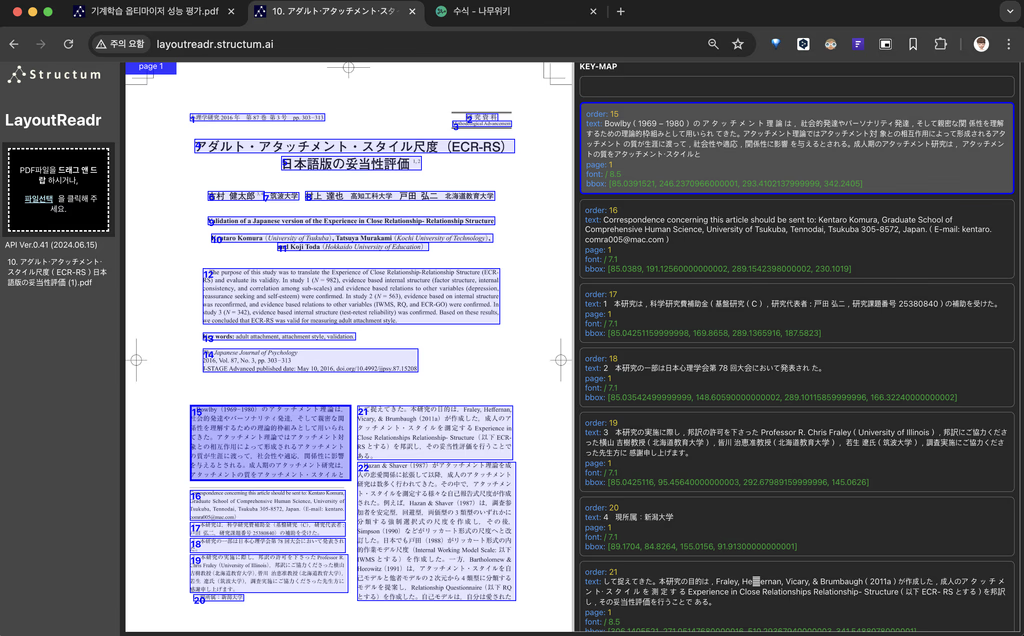
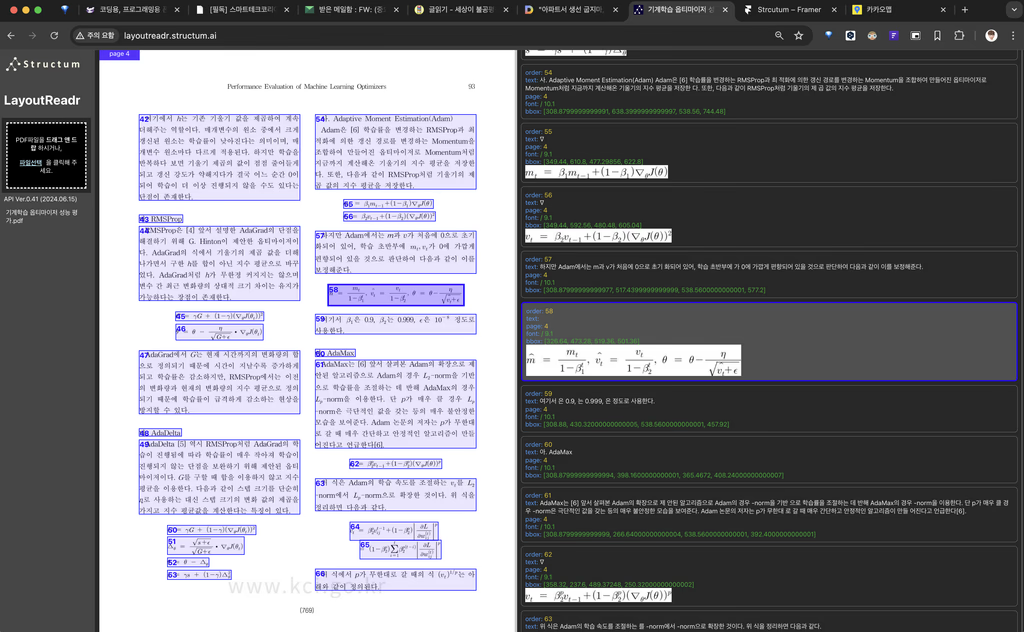
계약서, 약관, 기술 문서 등에 포함된 수식을 정확하게 인식하여 고해상도 이미지로 추출합니다.
향후 마크다운 포맷 지원도 제공할 예정입니다.
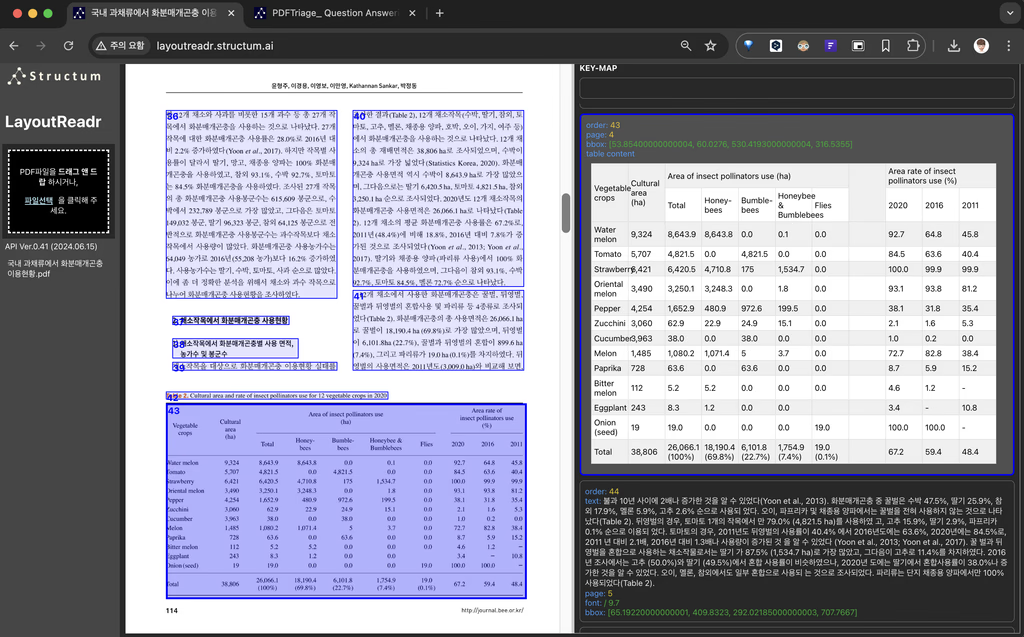
문서 내 핵심 정보가 담긴 표를 정확하게 인식하고 구조화된 데이터로 변환합니다.
복잡한 병합 셀과 다층 헤더 구조도 손실 없이 추출합니다.
언어모델 + 문서처리 + 클라우드 DB
추출된 문서 데이터를 효과적으로 활용할 수 있는 통합 플랫폼을 제공합니다.
고도화된 검색 기능, 언어모델 연동, 클라우드 기반 문서 관리 시스템으로 기업의 지식 자산을 체계적으로 구축하고 활용할 수 있습니다.
현재 플랫폼 서비스 준비 중입니다